Current Projects
 |
Using keystrokes to predict social dynamics in online dialogueWhen we speak to a person face-to-face, we gain information not just from the words being spoken, but also from prosodic elements of speech such as tone of voice and rate of speech. However, when we interact with people in a text-based environment, all of the information gained from non-lexical sources is lost. The aim of my thesis is to locate the information normally contained within speech prosody in the typing production patterns. In many ways, these patterns are typing analogs of prosodic variations in spoken language production. By measuring fine-grained variations in typing patterns, I aim to understand latent social motivations behind the overt lexical representations produced in text-based communication.Eventually these findings can be used to create explicit representations of information lost without spoken prosody, in hopes of making text-based communication a more rich and informative form of communication. This can be immediately applied to improving human-human text-based interactions, and perhaps in the future allow for more successful interactions between humans and computer agents, e.g. chatbots. [Dissertation Prospectus] |
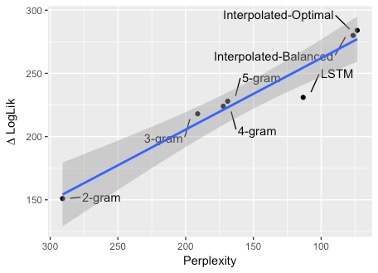 |
Using Language Models to Understand CognitionDo better language models better predict cognitive processes measured by eye-tracking? Using a neural net-based language model, we use generalized additive mixed models (GAMMs) to conclude that language models with lower perplexity can better model human cognition (eye-tracking data). We are also investigating the distinct influence of lower-level (local) statistics such as transitional probability versus surprisal’s effects on processing.Goodkind, A. & Bicknell, K. (2018) Predictive power of word surprisal for reading times is a linear function of language model quality [Code] **Best Paper Award @ CMCL 2018** |
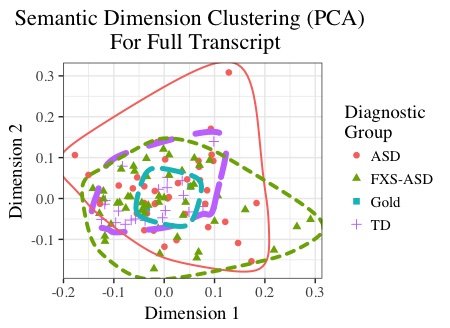 |
Linguistics and AutismConverting clinical transcripts into word vectors, we analyze semantic similarity in both typically-developing children (TD) and children with autism spectrum disorder (ASD). Our initial findings show that the cosine differences between children with ASD and TD children are significantly different when compared to a gold standard.Goodkind, et al. (2018) Detecting Language Impairments in Autism: A Computational Analysis of Semi-structured Conversations with Vector Semantics [Code] |
Back Burner
Human Behavior When Interacting With a Chatbot or Another Person This research also uses keystroke-production data as a way to understand human-computer interaction at a deeper level.By looking at keystroke timing during discourse, we can better understand underlying cognitive processes and optimize interfaces and agents to maximize collaborative success.
Among other investigations, we focus on these research questions:
- How does anomalous behavior, such as a prolonger pause or a mistake, from a conversational partner affect a user’s impression of their partner? Does it matter if their partner is a computer or another person?
- When we imitate our conversational partner (linguistic alignment), do we use the same cognitive resources to produce aligned text as we use when producing original text?
- Does a user’s impression of their partner, especially whether they are another person or a computer, affect their overall typing production and ways of interacting?
Past Projects
Keystroke Dynamics
- Typing patterns are unique to individuals. Just as everyone has a unique voice, such as pitch, rate of speech, and vocabulary, everyone has a unique way of typing. We frame typing patterns by the keystroke’s linguistic context, such as the word within which the keystroke was produced, or that word’s lexical category. For example, a typist might produce TH differently in a noun versus in a verb.
We utilize keystroke dynamics for two tasks: individual identification and cohort identification. The first task uses keystroke dynamics to better identify an individual. The latter task uses keystroke dynamics to try to predict a typist’s demographics, e.g. native language or gender, from their typing patterns.
- I’m also interested in how best to visualize keystroke data. The paper below is a dashboard I created for researchers. For my thesis, I am also interested in how keystroke data can best be shared with a conversational partner, to improve the conversation. For example, if keystroke patterns imply that a user is confused, then perhaps the speaker should re-explain what they are saying.
- Some questions that still vex me:
- How do temporal patterns surrounding typing reflect cognition and language familiarity?
- Why do we pause in the midst of typing?
- Do certain linguistic phenomena induce pauses in typing?
Multi-word Expressions
- Multi-word expressions (MWEs) are phrases such as “kick the bucket” or “a lot” which are made up of multiple words but are single lexical units. I study how we store and retrieve these types of lexical units in working memory. According to current hypotheses, MWEs are stored as a single unit, rather than word by word. My current research investigates how this is realized during language output, specifically typed text.
Resources
- How to write a great research paper
- My own LaTeX template inspired by this incredible talk: https://github.com/angoodkind/paper_inspiration